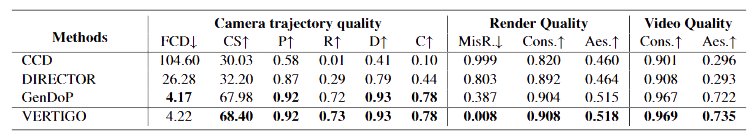Abstract

Cinematic camera control relies on a tight feedback loop between director and cinematographer, where camera motion and framing are continuously reviewed and refined. Recent generative camera systems can produce diverse, text-conditioned trajectories, but they lack this ``director in the loop'' and have no explicit supervision of whether a shot is visually desirable. This results in in-distribution camera motion but poor framing, off-screen characters, and undesirable visual aesthetics.
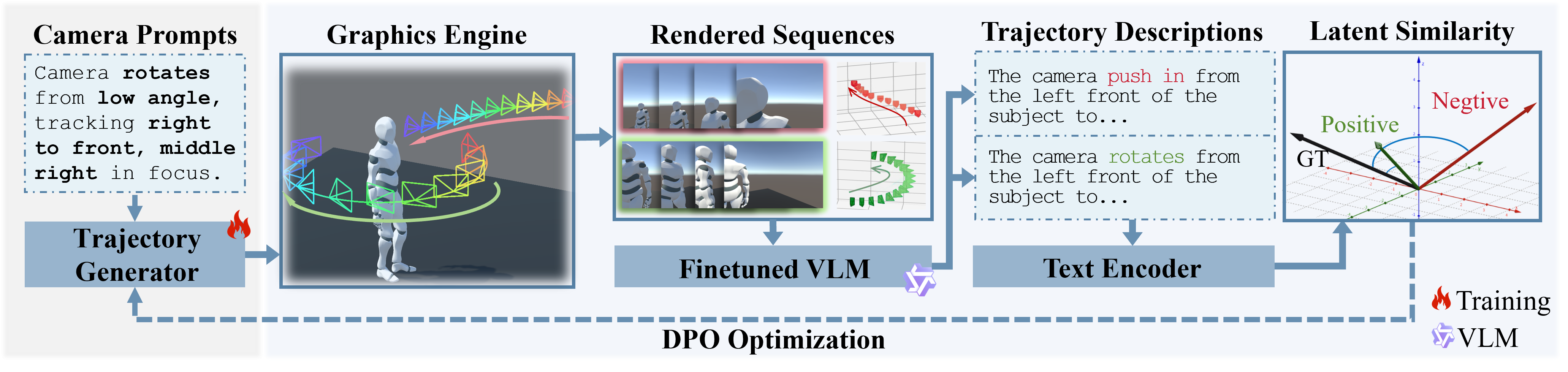
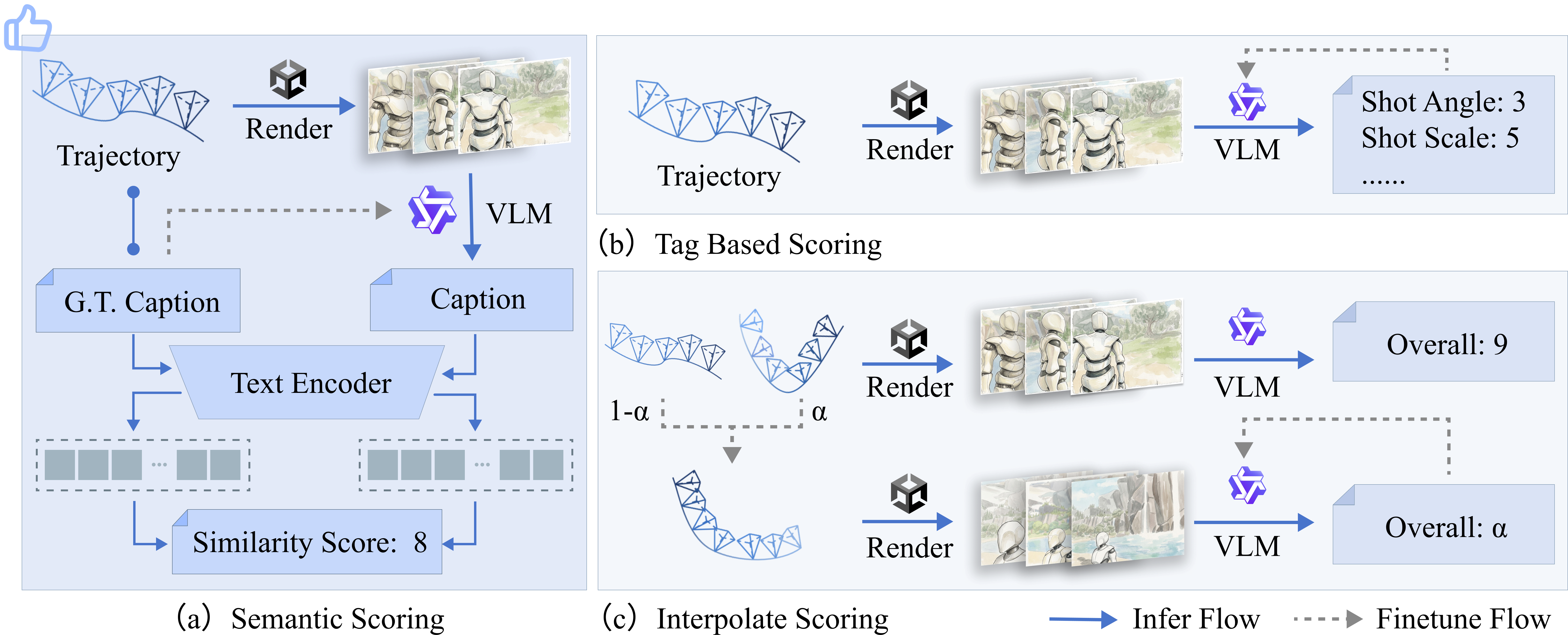
In this paper, we introduce VERTIGO, the first framework for visual preference optimization of camera trajectory generators. Our framework leverages a real-time graphics engine (Unity) to render 2D visual previews from generated camera motion. A cinematically fine-tuned vision–language model then scores these previews using our proposed cyclic semantic similarity mechanism, which aligns renders with text prompts. This process provides the visual preference signals for Direct Preference Optimization (DPO) post-training.